
 NLP with DeepLearning (9) - PLMs
NLP with DeepLearning (9) - PLMs
준지도 학습 (SSL; Self-supervised Learning) 비지도(Unsupervised), 지도(supervised) 학습은 많이 들어봤어도, 준지도(self-supervised) 학습은 입문자에게 낯설다. 단어 뜻을 토대로 유추해보면, 자기가 스스로 label을 생성하는 것이라고 유추해 볼 수 있겠다. 사람이 레이블링을 하는 것은 많은 리소스가 들어간다(그래서 따로 외주를 주는 것). 준지도 학습에서 레이블들은 입력으로 넣지 않은 나머지 데이터들이 y 삼아서 예측하도록 학습한다. "I love ___ go to school." 위 문장의 예시에서 빈 칸을 예측하는 태스크를 준지도 학습으로 해결하고자 한다면, 빈 칸을 제외한 나머지 단어들을(토큰) 다른 단어(토큰)들로 예측하도록 학습시키는 ..
 NLP with DeepLearning (8) - Text Classification
NLP with DeepLearning (8) - Text Classification
텍스트 분류는 어떠한 문장이 주어졌을 때, 그 문장이 속할 클래스의 확률을 구하는 것이다. 가격도 싸고 상품 품질은 괜찮은데 배송이 늦어서 화가 나네요. 항목 분류 품질 긍정 배송 부정 가격 긍정 종합 부정 위의 예제와 같이 문장이 input으로 들어오면, 전처리한 임베딩을 통해서 학습된 모델의 분류 방식에 따라서 분류하는 식이다. RNN & CNN ensemble RNN 먼저 one-hot vector를 입력으로 받아서 embedding layer에 넣어주고, Bi-directional RNN을 통해 출력을 얻는다. 마지막 time-step값을 softmax layer에 통과시켜 각 클래스별로의 확률값을 얻는다(BPTT). 자연어 생성과는 다르게 auto-regressive가 아니기 때문에, 입력을 한..
 Building ML Pipelines 따라잡기 (6) - 모델 학습
Building ML Pipelines 따라잡기 (6) - 모델 학습
TFX Trainer TFX Trainer 컴포넌트는 파이프라인의 학습 단계를 처리한다. 이 컴포넌트의 주요 프로세스에 대해서 정리하면 아래와 같다. run_fn() 함수를 찾아서 학습 프로세스를 실행하는 진입점으로 사용한다. run_fn() 함수는 input_fn() 함수를 찾아 사용할 데이터 로딩을 일괄적으로 수행한다. 이 함수는 transform 단계에서 생성한 압축되고 전처리된 데이터셋을 로드할 수 있다. get_model()을 사용하여 컴파일된 케라스 모델을 가져온다. fit함수로 학습한다. 학습된 모델을 SavedModel 형식으로 저장하고 내보낸다. 예제 프로젝트의 run_fn() 함수 코드는 아래와 같다. def run_fn(fn_args): tf_transform_output = tft...
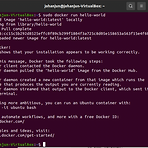 도커와 쿠버네티스 (2) - 도커 설치
도커와 쿠버네티스 (2) - 도커 설치
Docker 설치 가장 먼저 패키지 매니저인 apt-get을 업데이트한다. $ sudo apt-get update 도커 설치를 위한 prerequisites를 설치하려고 하는데, 역시나 에러가 떴다. 구글링해보니 lock이 걸려있는 경로를 지워줘야 한다고 한다. $ sudo rm /var/lib/apt/lists/lock $ sudo rm /var/cache/apt/archives/lock $ sudo rm /var/lib/dpkg/lock* 이후에 재부팅 하니 아래의 prerequisites 설치가 가능해졌다. $ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg \ lsb-release 다음은 GPG key를 설치한..
머신러닝 모델이 학습을 하려면, 학습할 수 있는 포맷의 데이터를 제공해야 한다(e.g. 카테고리 값들을 수치화). 일관된 전처리는 머신러닝 파이프라인에서 매우 중요한 요소이며, TFX 컴포넌트에서는 어떻게 제공 되는지 알아보자. TFT(Tensorflow Transform) TFT를 사용하면 전처리 단계를 텐서플로 그래프로 구성할 수 있다. TFT를 통해서 전처리를 표준화 해야하는 이유는 크게 3가지이다. 전체 데이터셋의 context에서 효율적으로 전처리 : TFT는 백그라운드에서 데이터를 통과하는 path를 관리하는 피처를 제공한다. 전처리 단계를 효과적으로 확장 : TFT는 내부적으로 아파치 빔을 사용하여 전처리 알고리즘을 실행하기에, 빔 백엔드에서 전처리를 배포할 수 있다. 잠재적인 학습-서빙 왜..
 NLP with DeepLearning (5) - Minibatch
NLP with DeepLearning (5) - Minibatch
Minibatch 모델에 넣기 위한 코퍼스의 최종 모양을 만들어줘야 할텐데, 그 tensor의 모양은 다음과 같다. tensor를 보면, 몇 가지 문제점이 보인다. vocab이 sparse해지기 때문에 메모리의 낭비가 생긴다. 따라서 vocab을 one-hot vector가 아닌 index로 처리하는게 좋다. 문장의 길이가 다 다르기 때문에 극단적인 예로 어떤 문장은 두 단어로, 어떤 문장은 100단어로 구성되어있다면 오른쪽의 padding 토큰의 차이가 극명해지고, 계산 낭비가 이뤄진다. 2번의 문제를 해결하기 위해서는 length를 sorting하는 방법이 있다. 그리고 미니배치의 순서를 shuffling하면 된다. 실습 with TorchText 먼저 터미널을 통해서 tsv파일을 shuffle해줘야..
 NLP with DeepLearning (4) - Subword Segmentation
NLP with DeepLearning (4) - Subword Segmentation
먼저 토큰의 길이에 따라서 어떤 특징을 가지는 지 생각해보자. "나는 오늘 아침에 테니스를 치고, 시리얼을 먹었다."는 문장을 예시로 들자. 토큰의 길이가 길다는 것은 이 문장 자체를 유니크한 토큰으로 가정한다는 것이고, 그 만큼 전체 문서에서 등장할 가능성이 희박해진다. 반면에 토큰의 길이가 짧아지면 "나/는/오늘/아침/에/테니스/를/치/고/,/시리얼/을/먹/었다/." 와 같이 분절되는 것이고, 아침, 테니스 등의 명사와 조사등은 전체 문서에서 자주 등장하여 count가 올라갈 가능성이 높다(즉, 희소성이 낮아진다). 희소성이 높다는 뜻은 OoV(Out of Vocabulary)가 늘어난다는 뜻이다. 즉, 모델의 입장에서 "이게 뭐여? 처음보는 단어(문장)인데?" 라고 인식하게 될 것이다. 모델의 성능..
 Building ML Pipelines 따라잡기 (4) - 데이터 검증
Building ML Pipelines 따라잡기 (4) - 데이터 검증
Garbage in, Garbage Out 머신러닝을 경험한 사람이라면 지겹도록 들은 말일 것이다(대부분은 Garbage가 안들어가도 Garbage Out되지만). 데이터를 선별하고 검증하지 않으면 모델이 제대로 학습하지 못한다. 데이터 검증은 파이프라인의 데이터가 피처 엔지니어링 단계에서 기대하는 데이터인지 확인하는 작업이다. 아래와 같은 작업들이 데이터 검증이라고 할 수 있다. 여러 데이터셋을 비교 시간이 지나 업데이트되면서 데이터가 변경될 때도 표시 이상치를 확인하거나 스키마(schema)의 변경 확인 새 데이터셋과 이전 데이터셋의 통계가 일치하는지도 확인 TFDV(Tensorflow Data Validation)를 통한 데이터 검증 TFX가 제공하는 패키지인 TFDV을 통하여 데이터를 검증해보자...
- Total
- Today
- Yesterday
- productresearch
- DDUX
- 머신러닝
- 도커
- ML
- mlpipeline
- Oreilly
- 파이프라인
- Kubernetes
- torch
- pmpo
- 스타트업
- MLOps
- dl
- docker
- PM
- Bert
- deeplearning
- productmanager
- productowner
- PO
- container
- nlp
- 쿠버네티스
- Tennis
- 전처리
- 딥러닝
- 인공지능
- 머신러닝파이프라인
- 자연어처리
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |